
前回の記事では犬の顔に自動でモザイク処理をするAI開発の計画立てと開発環境構築について解説しました。

本記事では、前回立てた計画の最初のステップである、すでに学習されたモデルを使った人間にモザイク処理をするAIの実装について解説していきます。
使うモデルは物体検出で有名なYOLOv5を使います。
なお本記事の実装の参考にさせていただいたコードは以下の記事です。

この場を借りて感謝申し上げます。
本記事の成果物
先に本記事の実装で出来上がるAIのデモムービーをお見せします。
複数の人間をしっかりモザイク処理できていることが分かりますね。
当たり前ですがモザイク処理は動画編集ではなく、AIにお任せした結果です。
学習済みのモデルのダウンロード
始めに学習済みのモデルをダウンロードします。
以下がYOLOv5のGitHubリポジトリのリンクです。
リンク先に行き、下の方にスクロールすると以下のような表が現れます。
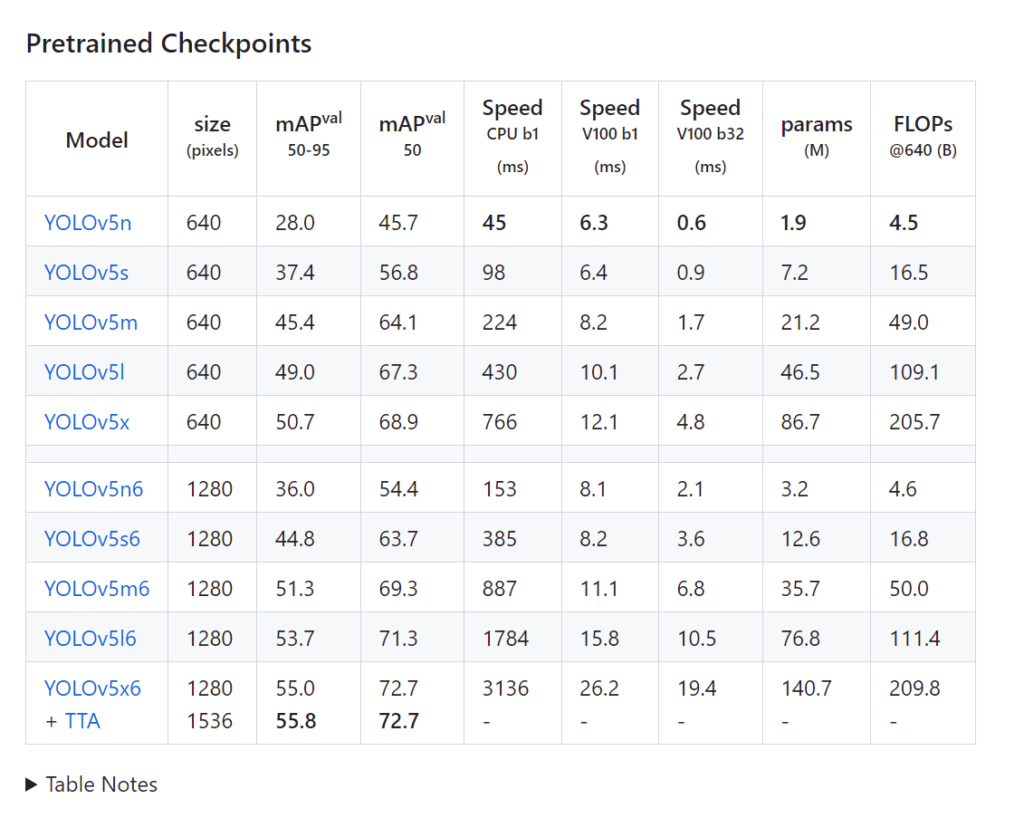
処理速度やモデルの精度を比較して、適切なモデルをクリックしダウンロードします。
今回はGPUを使わない都合で、なるべく処理が軽いYOLOv5nを選択しました。
クリックするとyolov5n.ptというファイルがダウンロードされます。
このファイルを以下フォルダ構成のように配置してください。
dog-face-mosaic-ai
|- env
|- models
|- yolov5n.pt
|- requirements.txt※ envやrequirements.txtは前回記事で作成したものです。
この学習済みのモデルは80種類の物体を学習しており、今回使う人以外にも電車、椅子、ケーキなどを検出することができます。
もし検出したい物体がこの80種の中に含まれているならば、モデルの学習をすることなくすぐにAIを実装することができますね。
ちなみこの学習済みモデルは犬も学習しているのですが、今回の目的である犬の顔ではなく全身を検出するため、別途モデルの学習を行います。
モデルの学習については、次の次の記事で解説します。
画像にモザイク処理をする関数の実装
まずプロジェクトフォルダ直下にmain.pyを作成します。
dog-face-mosaic-ai
|- env
|- models
|- yolov5s.pt
|- main.py
|- requirements.txtmain.pyに以下を追記します。(後ほど使うライブラリのインポートもここで記載しております。)
import argparse
import math
import os
import time
import cv2
import numpy as np
import torch
import tqdm
from logzero import logger
def mosaic(img: np.ndarray, alpha: float = 0.05):
try:
w = img.shape[1]
h = img.shape[0]
# int()で丸めると0になった場合にエラーとなるためceil()を使用
_w = math.ceil(w * alpha)
_h = math.ceil(h * alpha)
img = cv2.resize(img, (_w, _h))
img = cv2.resize(img, (w, h), interpolation=cv2.INTER_NEAREST)
return img
except Exception as e:
logger.error(f"Error mosaic : {e} (w={w} h={h} alpha={alpha})")ざっくり解説しますと、まず入力した画像の解像度を下げます。
どのくらい画素数を下げるかはalphaで制御します。
例えば256×256の画像を入力した際、alphaがデフォルトの0.05であった場合は、256×0.05の値を小数点以下切り上げた13、つまり13×13ピクセルの画像にします。
そして解像度が下がった画像を元の解像度に戻します。
このとき足りない画素を最近傍補間するため、元の画像と解像度は同じだが、モザイクがかかったような画像となるといった処理をしています。
動画の1フレーム毎にモザイク処理をする関数の実装
続いて、動画とモザイク処理したい座標を渡してモザイク処理する関数を実装します。
後ほどの実装で分かるのですが、YOLOv5では動画を入力することで各フレーム毎に物体検出した結果を返してくれます。
各フレームのリストをframes、各フレーム毎の物体検出結果をresults、またモザイク処理したフレームを書き込むwriterという引数を受け取るようにこちらの関数を実装します。
先に次項のメイン部分の実装を見てから、こちらのコードの説明に戻ってくるのでも良いかもしれません。
それでは実装が以下となります。
def write_moseic_to_frame(writer, frames, results):
for frame, xyxys in zip(frames, results.xyxy):
for xyxy in xyxys:
xmin = int(xyxy[0])
ymin = int(xyxy[1])
xmax = int(xyxy[2])
ymax = int(xyxy[3])
frame[ymin:ymax, xmin:xmax] = mosaic(frame[ymin:ymax, xmin:xmax])
writer.write(frame)処理自体はシンプルで、各フレーム毎に物体が検出された座標部分を前項で作成したモザイク処理関数に渡して順次モザイク処理していくものとなっています。
メイン関数の実装
最後の動画の読み込みやYOLOv5で物体検出などあれこれする部分を実装します。
受け取る引数は動画のパスとモデルのパス (例えば本記事の最初の方にダウンロードしたyolov5n.ptまでのパス)、そしてバッチサイズです。
バッチサイズとはYOLOv5で1回の推論で物体検出を行うフレーム数です。一度に動画すべてに対して物体検出することもモデル的には可能なのですが、PCのメモリに乗り切らないことを考慮して分割して物体検出できるようにしました。
実装は以下です。
def main(video_path: str, model_path: str, bacth_size: int = 64) -> None:
# video
video = cv2.VideoCapture(video_path)
frame_count = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
frame_rate = video.get(cv2.CAP_PROP_FPS)
logger.info(f"frame count: {frame_count}")
logger.info(f"FPS: {frame_rate}")
w = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
size = (w, h)
logger.info(f"video size: {size}")
# model
model = torch.hub.load(
"ultralytics/yolov5",
"custom",
path=model_path,
)
model.classes = [0] # filter by class
# output
fmt = cv2.VideoWriter_fourcc("m", "p", "4", "v")
writer = cv2.VideoWriter(
video_path.replace(".mp4", "_mosaic.mp4v"),
fmt,
frame_rate,
size,
)
try:
# detect
# frameをすべてメモリに載せることができない可能性も考慮して
# ミニバッチを都度作成してモデルに入力している
i = 0
j = 0
frame_list = []
for frame_idx in tqdm.trange(frame_count): # tgdm(range(frame_count))
i += 1
video.set(cv2.CAP_PROP_POS_FRAMES, frame_idx)
ret, frame = video.read()
if ret == False:
j += 1
continue
frame_list.append(frame)
if (i == bacth_size) or (frame_idx == frame_count - 1):
results = model(frame_list)
write_moseic_to_frame(writer, frames=frame_list, results=results)
i = 0
frame_list.clear()
except Exception as e:
writer.release()
video.release()
logger.error(f"{e}")
# finish
if j != 0:
logger.warning(f"n of ret: {j}")
writer.release()
video.release()ここで重要なのがコメントでfilter by classと書かれている箇所です。ここで今回0を指定していますが、この0が学習済みのモデルにおける「人間」のラベルに対応しています。例えば5とかにするとバスを検出した結果のみをフィルターして、後ほどのモザイク処理に渡すようになっています。
検出対象とラベルの関係は例えば以下で調べることができます。
print(model.names)スクリプト実行時にパスを受け取れるようにする
メイン部分は実装できたので後はインターフェース部分です。
スクリプトを実行する際に推論対象の動画のパスと使用するモデルのパスを受け取れるようにします。
このようなときはargparseを使いましょう。
実装は以下です。
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument("--video", type=str)
parser.add_argument("--model", type=str)
return parser.parse_args()
if __name__ == "__main__":
start_time = time.time()
opt = parse_opt()
video_path = opt.video
model_path = opt.model
main(video_path=video_path, model_path=model_path, bacth_size=128)この実装ではバッチサイズは128で決め打ちしていますが、こちらもスクリプト実行時の引数で設定できるようにしてもいいですね。
動画中の人間にモザイク処理してみる
最後に作成したプログラムを実行してみましょう。
python main.py --video /your/video/path --model ./models/yolov5n.pt動画のパスは適切なパスに変更してください。
実行するとプログレスバーが進行し、モザイク処理が終了すると元の動画と同じ階層にモザイク処理された動画が出力されています。
動画を確認してもらうと以下のような人間にモザイクがかかった動画が作成されているはずです。
最後に
ここまでお読みいただきありがとうございます。
一旦本記事はここまでにいたします。
次の記事は自作の学習モデルを作るための学習データの作成方法についての解説です。


